Craigslist Scrape Methodology
August 30, 2018
It’s hard to get thorough rental price data. Private data from companies like Zillow or RealQuest can be prohibitively expensive, and many cities don’t keep track of rents or contracts.* Even if a city does record rents, you might be interested in a research question that involves multiple rental markets, and getting data sets from different cities to play nice together can be challenging.
I ran into both problems when I decided to look at changing rents in San Francisco. The city doesn’t track rental agreements, and it’s also part of a deeply enmeshed regional housing market. For many research applications, looking at San Francisco in isolation isn’t enough — you really need data on the entire Bay Area.
Getting Rents from Craigslist
Craigslist has become a major platform for the rental market in the United States. The site connects potential tenants with landlords who post listings containing information like price, bedrooms, square footage, photos, and descriptions.
Listings expire, but many of them have been archived by the Wayback Machine, a non-profit that maintains a library of past internet content by taking repeated snapshots of webpages. I wrote python code using the packages BeautifulSoup and Selenium to navigate through all of the Bay Area apartment listings archived by the Wayback Machine from September 2000 – July 2018. If you’re interested, you can check out the full description of the methodology below. I’ve also posted a walkthrough of the python code.
I’m sharing the data in the hope that it’s fun and useful for other people as well. It’s covered under a GNU General Public License v3.0. If you use it, please make sure to cite.
Data Limitations
While there’s a lot to learn from the universe of archived historic Bay Area Craigslist rental prices, there are as always issues to keep in mind. There are three main drawbacks to using this data.
First, Craigslist data do not capture the entire rental market. There is reason to expect that it’s systematically missing the highest end of the market, which may be dominated by real estate agents, and the lowest end of the market, which may be dominated by word of mouth.
Second, it is not complete in time: the Wayback Machine only archives websites sporadically. Luckily, it’s likely that the timing of archive events is random, so the data can still be used for causal inference. (It’s hard to find out exactly how Wayback decides when to archive which pages.) However, this does mean that for some research applications, you may need to interpolate over time.
In addition, the Wayback Machine does not archive every listing on every date. Usually, it only archives the first 100-120 results (that is, you can’t click ‘next’ on the archived pages). While this reduces the amount of data we can recover, it probably doesn’t introduce bias: the top 100-120 results are whichever results were most recently posted when the archive event began.
Third, the data are not continuous (or perfectly reliable) in space, either. Some areas, like the Lake Merritt area of Oakland, have hundreds of postings over the entire 2000-2018 period. For these areas, you can look at very geographically-specific trends over time. But for other areas, like the small town of Jenner in Sonoma County, postings are sparse. Depending on your research needs, you may need to interpolate over space or to aggregate up to larger regions. Other times, Craigslist users failed to enter accurate location data or the location data can’t be matched for sure to a specific place. For example, if someone entered ‘4th St’ instead of a neighborhood, it’s not possible to tell which Bay Area town it’s in.
Creating this data set involved two major steps: first, scraping the data, and second, cleaning it. If you plan to use the data, please read about the cleaning process so you understand how the variables were constructed.
A. Scraping the Data
Step 1:
The Wayback Machine provides a calendar of every date on which it’s archived a given url. For example, the calendar below marks every date on which http://sfbay.craigslist.org/apa has been archived with a circle.
My first step is to scrape a list of all of these circled archive date urls. I do this for every year for the general Bay Area link http://sfbay.craigslist.org/apa and for the regional links http://sfbay.craigslist.org/sfc/apa, http://sfbay.craigslist.org/scz/apa, http://sfbay.craigslist.org/eby/apa, http://sfbay.craigslist.org/nby/apa, http://sfbay.craigslist.org/sby/apa, and http://sfbay.craigslist.org/pen/apa.
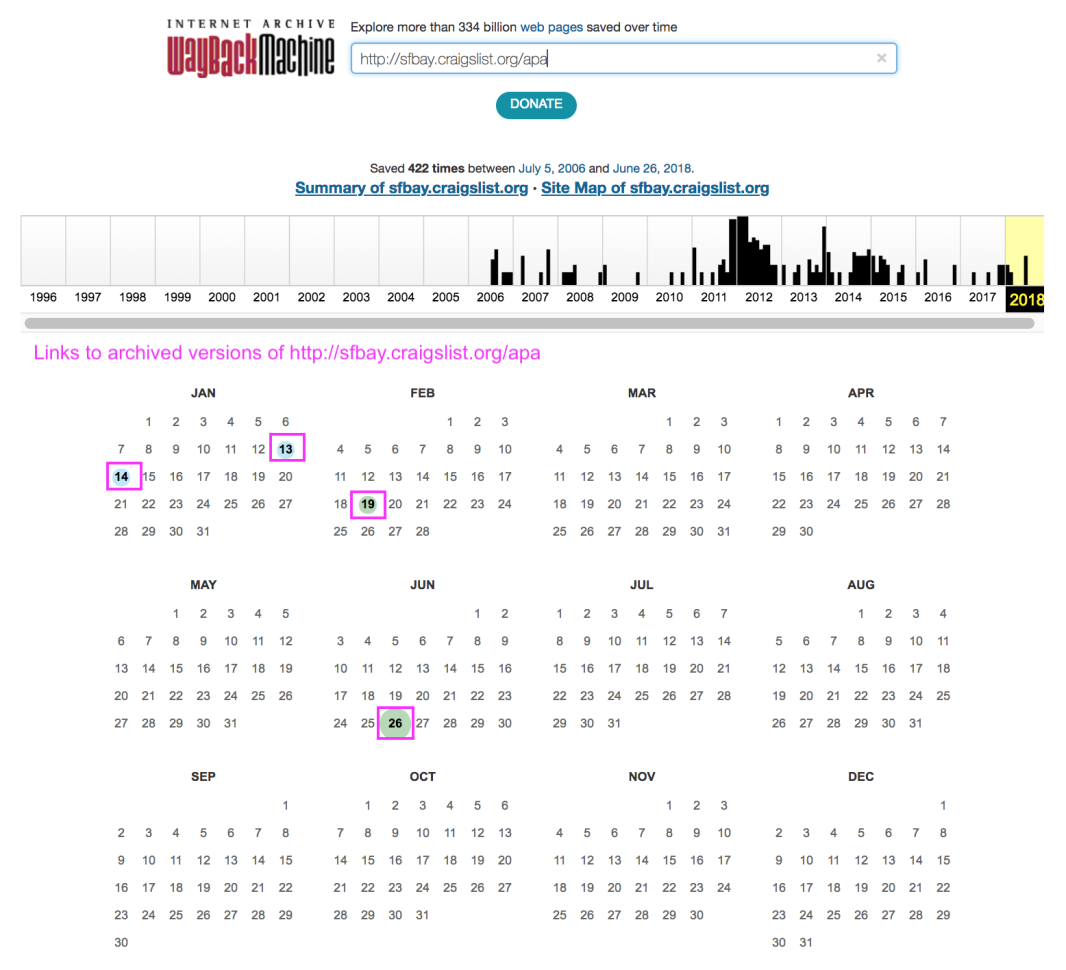
Step 2:
Each of these archive date urls leads to a search landing page, like this:
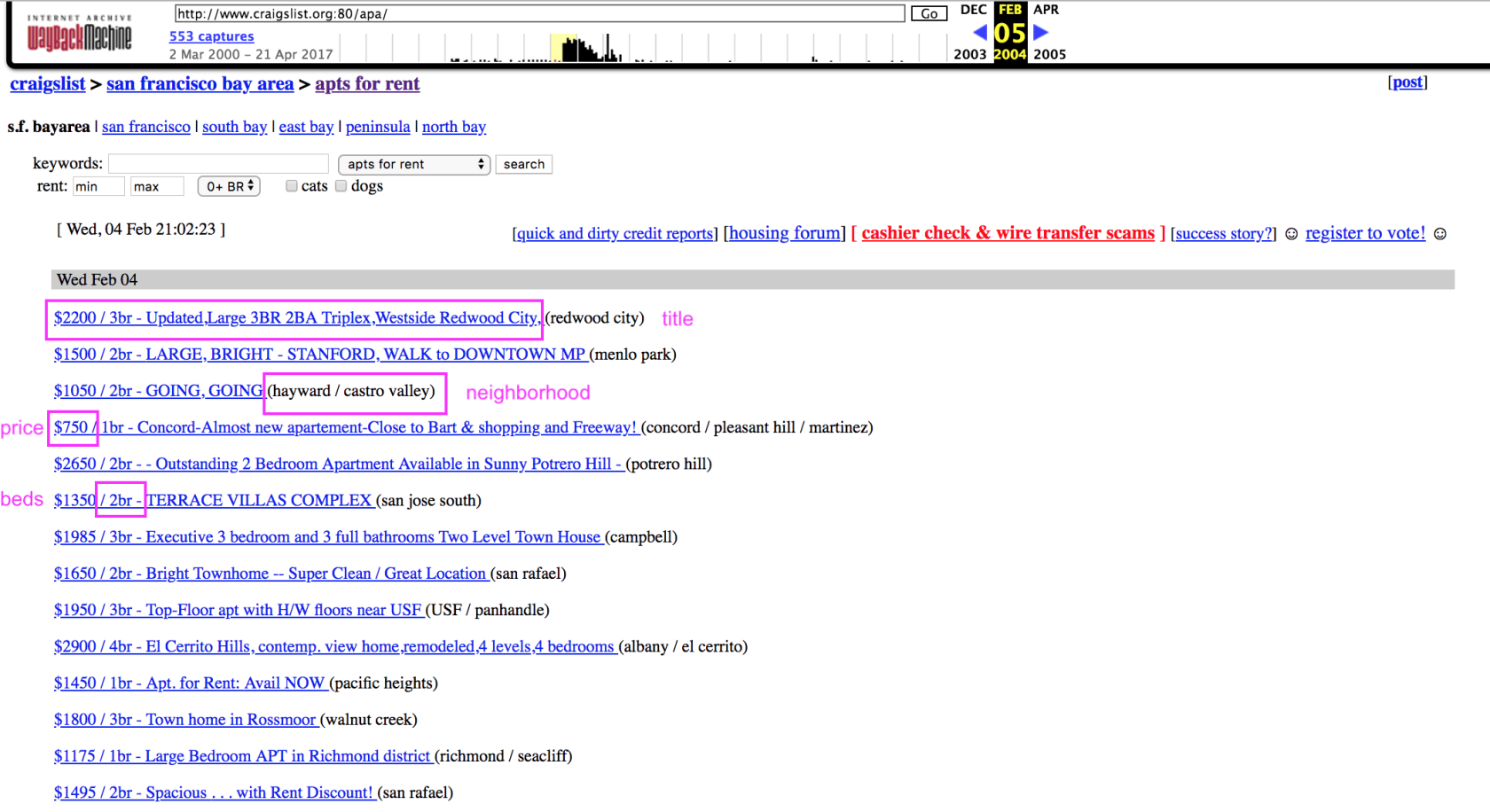
Step 3:
For each of these pages, I scrape all of the listing information available in the html. This always includes title, posting date, and neighborhood. Often, it also includes an individual post id, price, number of bedrooms, number of bathrooms, and square footage. Sometimes it also includes latitude and longitude. Sometimes the Wayback Machine even archives individual posts. I use the python package Selenium to ‘click’ on each link to scrape the data from the listing page:
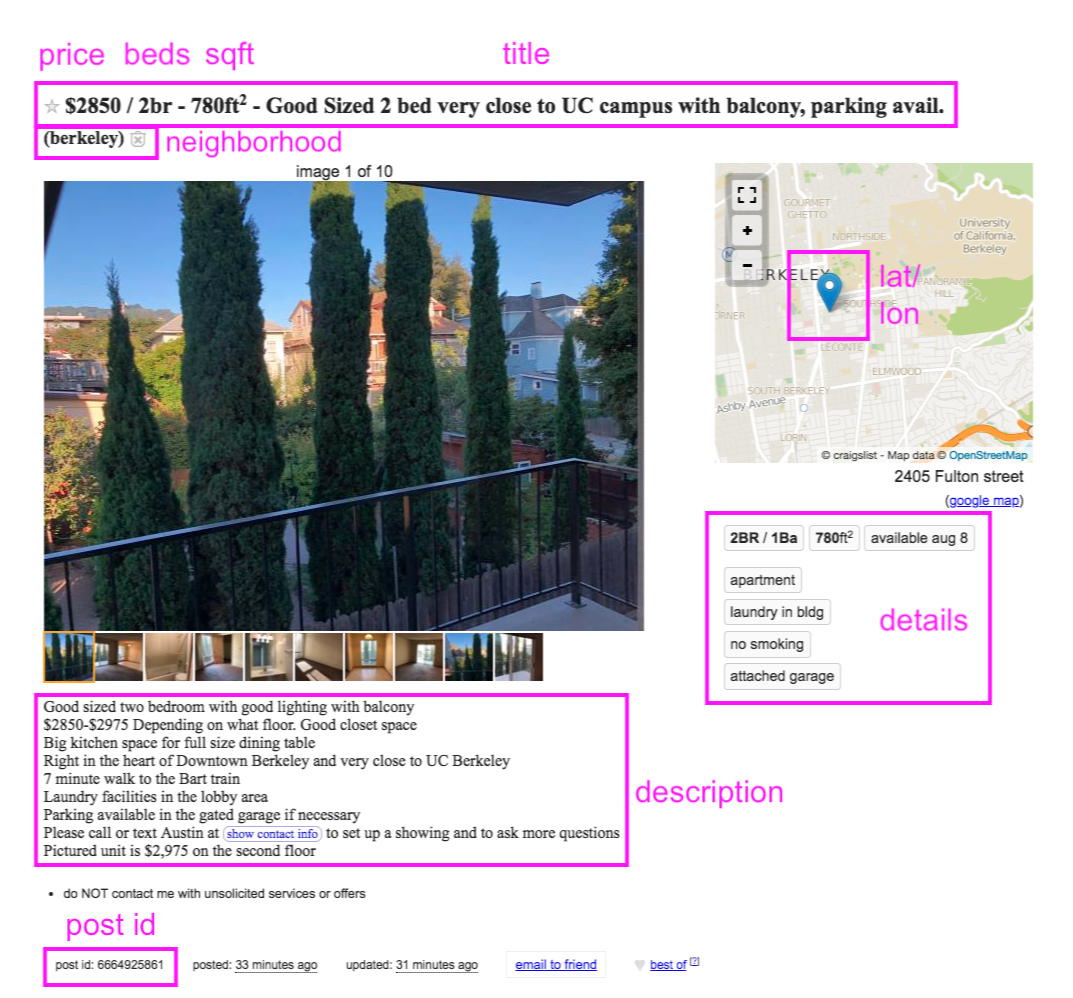
As you can see, this offers a second chance at scraping variables like price, bedrooms, bathrooms, and square footage that may have been NA on the landing page. It also lets me capture the full text of the description, the ‘details’ captured in the buttons under the map, and the lat/lon from the map itself.
You can read a walkthrough of the python code for each of these steps here.
B. Cleaning the data
Craigslist lets users input whatever they like in each field, so things can get…messy. Sometimes people don’t input the neighborhood where they should, or they add special characters like:
$2174 / 2br – 885ft2 – ♥ Beautiful Petaluma apartmentsI used R to clean the data and to fill in the blanks, when possible, based on the content of the title and/or description. I started out by using regular expressions to extract price, bedroom, and bathroom information from the title and/or description and skimmed the data to make further manual corrections. I’m sure more could be made.
The bulk of the work was cleaning the location information. Some of the neighborhoods are easy to resolve — take Potrero Hill, Downtown Berkeley, and San Rafael, for example. Others are trickier. I grouped some micro-neighborhoods into larger areas, such as “USF / anza vista” and “marina / cow hollow” in San Francisco. Oakland got grouped into six main areas and San Jose into five. I chose these groupings to be geographically sensible and to generate a reasonable number of observations in each bucket. These larger neighborhoods may work great for your purposes, or you may want to start from the raw data to create your own.
Sometimes it isn’t possible to tell locations apart. For example, “telegraph” might mean either Telegraph Hill in San Francisco or the Telegraph Avenue area in Berkeley. In these cases, I set the neighborhood as “sf bay area.” Other times, it’s possible to tell which region a post is in. In those cases, neighborhood is given as “san francisco,” “oakland,” “san jose,” “east bay,” “north bay,” or “south bay,” as appropriate. If I only have one observation of a given location, I set the neighborhood as “sf bay area” as well.
Whenever I have lat/lon, I reverse geocode to recover the address. Whenever I have the address, I geocode to recover the lat/lon.
The variable `room_in_apt’ is a dummy equal to 1 when the posts includes phrases like “seeking roommate” or “room in our 3-bedroom apartment.” I’m sure many more of the 1-bedrooms are really one room in larger apartments, but without the description text it isn’t possible to identify them.
*The city of Berkeley is a phenomenal exception — you can browse the rental history of all Berkeley apartments here.