Walkthrough: Writing Python Code for Scraping Craigslist
August 30, 2018
This was my first time web scraping with python, and there were a lot of long frustrations in between the successes. On this page, I’ll walk through some sample code to illustrate what I did and/or to help someone else get started with their own code.
The sample code here is simplified for clarity. In reality, Craigslist has changed its page structure many times since 2000, and I had to write variations of this sample code to play nicely with each variation of page structure. Depending on the page structure of the data you want, you’ll have to modify this starter code a lot. It’s intended as a manual rather than a car you can drive right off the lot.
This code uses two key python packages, BeautifulSoup and Selenium. BeautifulSoup lets you scrape content from html elements, and Selenium lets you virtually click through web pages.
Step 1: Get the list of links you want to scrape
The Wayback Machine provides a calendar of every date on which it’s archived a given url. For example, the calendar below marks every date on which http://sfbay.craigslist.org/apa has been archived with a circle.

The first step is to scrape a list of all of these circled archive date urls. I do this for every year for the general Bay Area link http://sfbay.craigslist.org/apa and for the regional links http://sfbay.craigslist.org/sfc/apa, http://sfbay.craigslist.org/scz/apa, http://sfbay.craigslist.org/eby/apa, http://sfbay.craigslist.org/nby/apa, http://sfbay.craigslist.org/sby/apa, and http://sfbay.craigslist.org/pen/apa.
I do this by looping over each year and each region. The first step of the loop constructs the links to the archive calendar for each of these regions in each year. Then the code follows each link using Selenium, and scrapes the archive dates using BeautifulSoup.
The first step is figuring out what are these archive date links are called in the html, so we construct the links. To see the elements of any web page, just right-click and select `Inspect’ from the dropdown menu. Browse through the html until you find the elements you’re interested in. They’ll be contained in a labeled chunk — you can recover the information you’re interested in by calling the name of the chunk.
This chunk sets up the packages that will be used and then extracts the link names:
# Open python
python
#
# Set up the packages you'll be using
import csv
import requests
from bs4 import BeautifulSoup
import os
import pandas as pd
import numpy as np
import selenium
from selenium import webdriver
# Create the csv you'll be writing to
make = open('historic.csv', 'a')
make.close()
# Open the browser tab that you'll control with your code
browser = webdriver.Chrome()
# List the years you'll loop over
years = ["2003","2004","2005"]
# List the bay area regions you'll loop over
reg_list = ["sfc","scz","pen","sby","eby","nby"]
# Initialize your list
links = []
for y in years:
for i in reg_list:
try:
calpage = "https://web.archive.org/web/" + str(y) + "0101000000*/http://www.craigslist.org/" + str(i) + "/apa/"
browser.get(calpage) # doing this twice ensures that it loads correctly
browser.get(calpage)
try:
cal = browser.find_element_by_css_selector('#wb-calendar')
except:
time.sleep(5) # sometimes the browser loads slowly--just try again
cal = browser.find_element_by_css_selector('#wb-calendar')
html = cal.get_attribute("innerHTML") # get the calendar's html content
soup = BeautifulSoup(html, 'html.parser') # turn it into a soup
links = soup.find_all("a") # the name of the chunk containing links
for a in links: # grab each one and format it into a coherent url
url = "https://web.archive.org" + str(a).split('"', 1)[1].split('"',1)[0]
if url not in links: # if we don't already have it, add it to the list
links.append(url)
except: # if a page does not exist, continue to the next one
continueStep 2: Write the function that does the scraping
Now we have a list of the archive urls that we want to follow. Each one leads to a search landing page, like this:
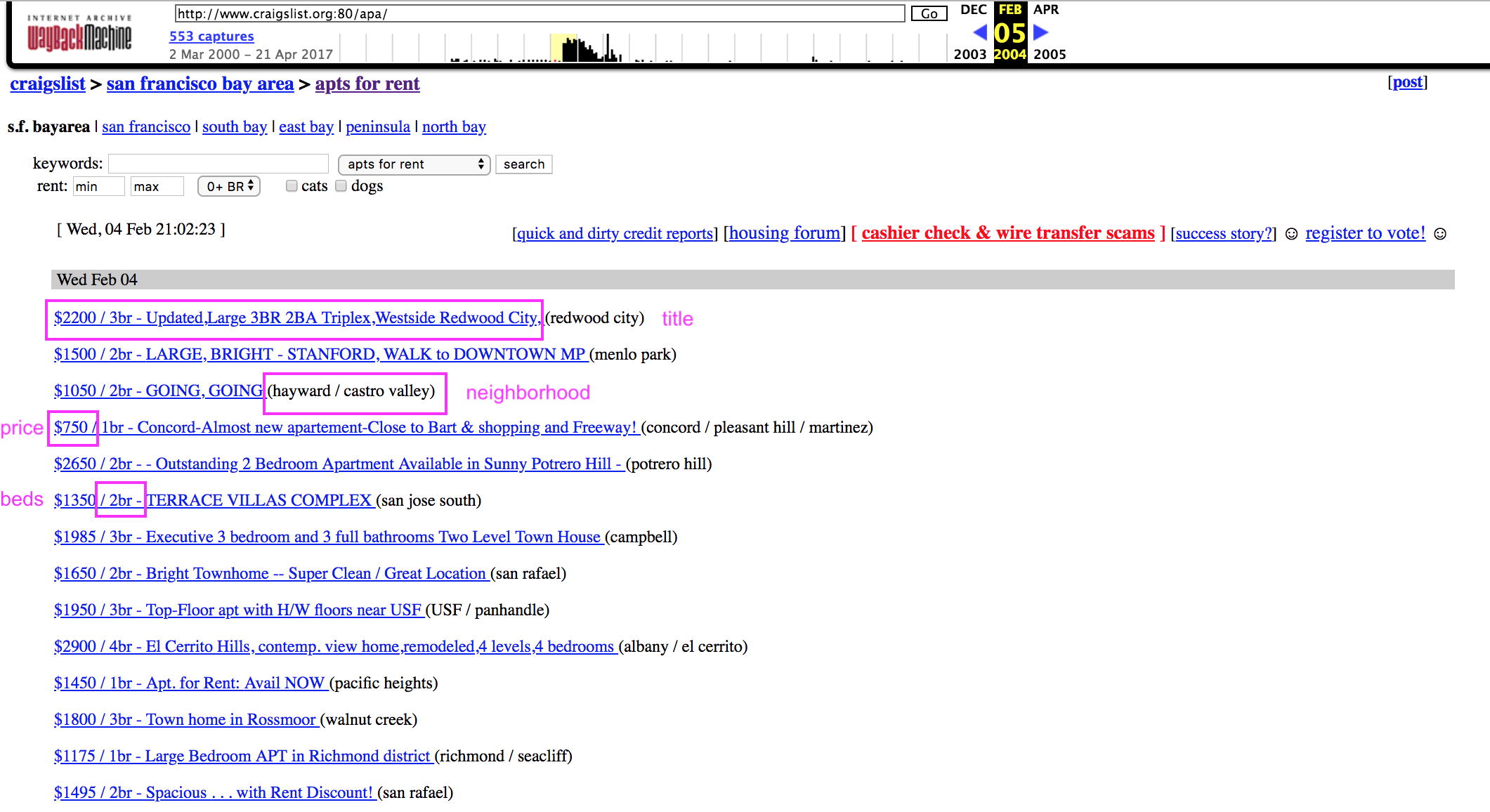
For each post, we need to capture the posting date, title, neighborhood, and then try to follow the link to get more information. Not all of the individual posts are archived, though — we need to write code that will attempt to follow the link, but continue if it isn’t possible. In the best case scenario where the individual post is archived, we can ‘click’ on it to scrape the data from the listing page:
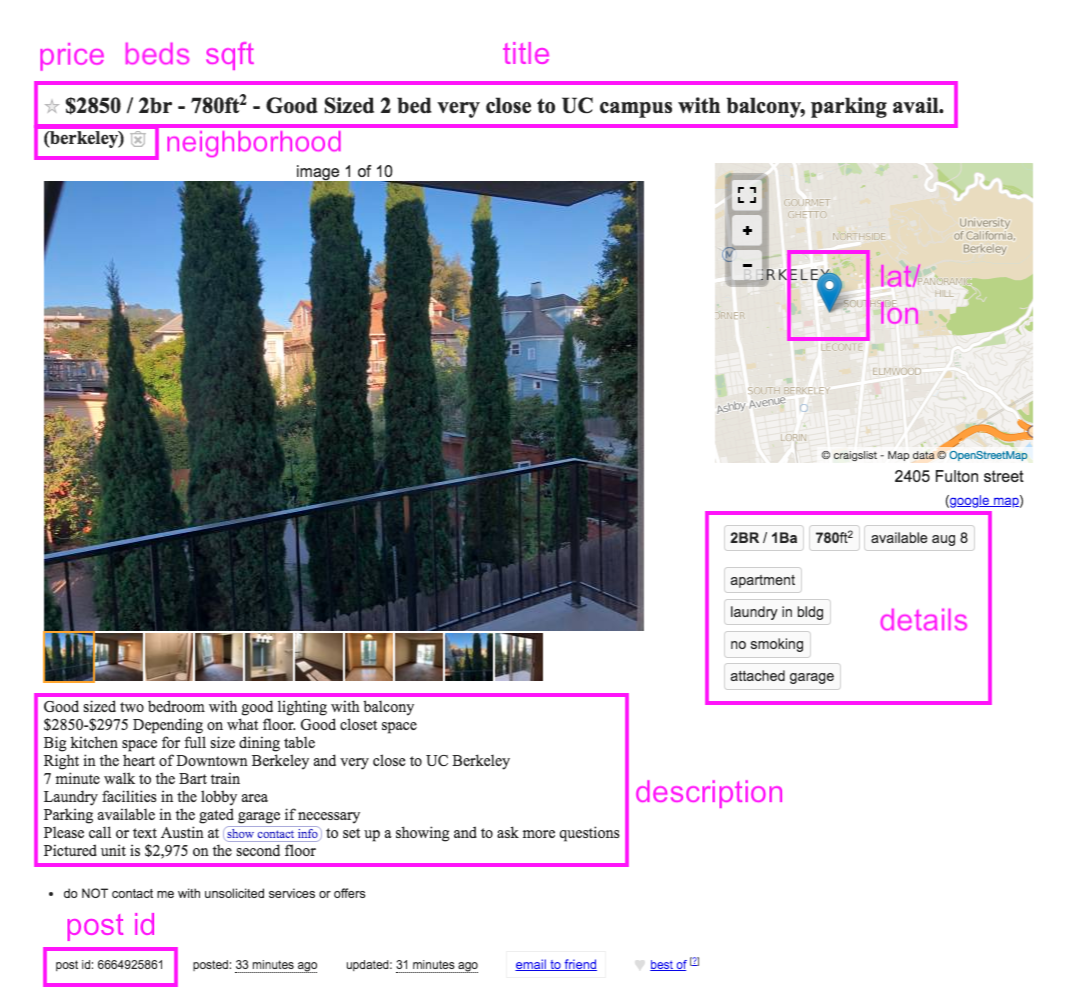
Finally, sometimes the Wayback Machine has archived the next 100 posts. Our function should also try to click the next button and scrape those pages, too.
def historic_scrape(n, soup, date_plus):
# Extract the listings
list_of_listings = soup.find_all('li', attrs = {'class' : 'result-row'})
# Loop over all listings on that page
for x in list_of_listings:
post_id = str(x).split('data-id="',1)[1].split('"',1)[0]
try:
title = str(x).split("html",1)[1].split('html">',1)[1].split("<",1)[0] except Exception as e: title = "NA" date = str(x.a).split( "web/", 1)[1].split("/http:")[0][0:8] try: lat = str(x).split("latitude=",1)[1].split("data-longitude",1)[0] except Exception as e: lat = "NA" try: lon = str(x).split("longitude=",1)[1].split(">",1)[0]
except Exception as e:
lon = "NA"
try:
nhood = x.find('span', attrs= {'class':'result-hood'}).text
except Exception as e:
nhood = "NA"
try:
price = x.find('span', attrs= {'class':'result-price'}).text
except:
price = "NA"
try:
beds = x.find('span', attrs= {'class':'housing'})
except:
beds = "NA"
try:
sqft = x.find('span', attrs= {'class':'housing'})
except:
sqft = "NA"
# Enter the listing url to get additional info
listing_url = x.find('a')['href']
#try:
try:
lsoup = BeautifulSoup(requests.get(listing_url).content,'html.parser')
except:
address = "NA"
descr = "NA"
details = "NA"
try:
browser.get(listing_url)
time.sleep(5)
map = browser.find_element_by_xpath('//*[@id="map"]')
html = map.get_attribute("outerHTML")
csoup = BeautifulSoup(html, 'html.parser')
except:
csoup = "NA"
if csoup == "NA":
try:
browser.get(x.find('a')['href'] + "?lang=ko")
time.sleep(5)
map = browser.find_element_by_xpath('//*[@id="map"]')
html = map.get_attribute("outerHTML")
csoup = BeautifulSoup(html, 'html.parser')
except:
csoup= "NA"
else:
continue
try:
lat = str(csoup).split('latitude="',1)[1].split('"',1)[0]
except Exception as e:
lat = "NA"
try:
lon = str(csoup).split('longitude="',1)[1].split('"',1)[0]
except Exception as e:
lon = "NA"
try:
address = str(csoup).split('mapaddress">',1)[1].split("<",1)[0] except Exception as e: address = "NA" try: descr = lsoup.find('section', attrs={'id' : 'postingbody'}).text except Exception as e: descr = "NA" try: details = lsoup.find("p",attrs={ "class":"attrgroup"}) except Exception as e: details = "NA" #Write to csv with open("historic.csv",'a') as f: writer = csv.writer(f) writer.writerow([blank]) writer.writerow([post_id, date, nhood, price, beds, sqft, address, lat, lon, descr, title, details]) while(True): if no_error(n):# Cycle through every page of search results next_pg = url_prefix + date_plus + "/http://sfbay.craigslist.org:80/apa/index" + str(n) + ".html" soup = BeautifulSoup(requests.get(next_pg).content, 'html.parser') try: year = str(soup.find('form')).split('web/',1)[1].split('/',1)[0][0:4] except: year = "NA" if year == str(dateplus[0:4]): # Extract the listings list_of_listings = soup.find_all('li', attrs = {'class' : 'result-row'}) # Loop over all listings on that page for x in list_of_listings: post_id = str(x).split('data-id="',1)[1].split('"',1)[0] try: title = str(x).split("html",1)[1].split('html">',1)[1].split("<",1)[0] except Exception as e: title = "NA" date = str(x.a).split( "web/", 1)[1].split("/http:")[0][0:8] try: lat = str(x).split("latitude=",1)[1].split("data-longitude",1)[0] except Exception as e: lat = "NA" try: lon = str(x).split("longitude=",1)[1].split(">",1)[0]
except Exception as e:
lon = "NA"
try:
nhood = x.find('span', attrs= {'class':'result-hood'}).text
except Exception as e:
nhood = "NA"
try:
price = x.find('span', attrs= {'class':'result-price'}).text
except:
price = "NA"
try:
beds = x.find('span', attrs= {'class':'housing'})
except:
beds = "NA"
try:
sqft = x.find('span', attrs= {'class':'housing'})
except:
sqft = "NA"
# Enter the listing url to get additional info
listing_url = x.find('a')['href']
#try:
try:
lsoup = BeautifulSoup(requests.get(listing_url).content,'html.parser')
except:
address = "NA"
descr = "NA"
details = "NA"
try:
browser.get(listing_url)
time.sleep(5)
map = browser.find_element_by_xpath('//*[@id="map"]')
html = map.get_attribute("outerHTML")
csoup = BeautifulSoup(html, 'html.parser')
except:
csoup = "NA"
if csoup == "NA":
try:
browser.get(x.find('a')['href'] + "?lang=ko")
time.sleep(5)
map = browser.find_element_by_xpath('//*[@id="map"]')
html = map.get_attribute("outerHTML")
csoup = BeautifulSoup(html, 'html.parser')
except:
csoup= "NA"
else:
continue
try:
lat = str(csoup).split('latitude="',1)[1].split('"',1)[0]
except Exception as e:
lat = "NA"
try:
lon = str(csoup).split('longitude="',1)[1].split('"',1)[0]
except Exception as e:
lon = "NA"
try:
address = str(csoup).split('mapaddress">',1)[1].split("<",1)[0]
except Exception as e:
address = "NA"
try:
descr = lsoup.find('section', attrs={'id' : 'postingbody'}).text
except Exception as e:
descr = "NA"
try:
details = lsoup.find("p",attrs={ "class":"attrgroup"})
except Exception as e:
details = "NA"
# Append to csv
with open("historic.csv",'a') as f:
writer = csv.writer(f)
writer.writerow([blank])
writer.writerow([post_id, date, nhood, price, beds, sqft, address, lat, lon, descr, title, details])
n = n + 100
continue
else:
print("All listings have been scraped.")
break
else:
print("All listings have been scraped.")
break
else:
print("All listings have been scraped.")
breakStep 3: Run the function over the list of links you want to scrape
The function takes three inputs: n, the soup from the link we’re scraping, and something called date_plus. Both n and date_plus are used to cycle forward through the next 100 postings by constructing the correct url.
Finally, it’s nice to know how much progress you’ve made — the last line will print a success message after each page has been scraped.
for i in links:
first_page = "https://web.archive.org" + str(i).split( "href=\"", 1)[1].strip().split("\"",1)[0].strip()
soup = BeautifulSoup(requests.get(first_page).content, 'html.parser')
date_plus = str(soup).split("web/",1)[1].split("/http",1)[0]
historic_scrape(0,soup,date_plus)
print("***** Link" + str(i) + "completed *****")That’s it! As mentioned before, this is just sample code — because Craigslist page structure has changed so many times over the years, you will definitely need to modify it for your own purposes. This is just meant to offer a starting point. There are probably much more elegant approaches, too!